
Simulating Bird-oid Objects
As a part of HPC, I has to do a big semester long project. Specifically, I would need to do some simulation, demonstrate issues with scalability and implement some parallelisation to achieve performance with large working sets. This project ended up being quite fun, with a nice combination of real time rendering, multithreaded algorithm optimisation and data analysis.
 It also helped that I got to run stuff on UQ’s fancy HPC clusters with some cool visual output, quite fun indeed.
It also helped that I got to run stuff on UQ’s fancy HPC clusters with some cool visual output, quite fun indeed.
As infered from the above gif, my project was on boids, which is a multiagent simulation that replicates the flocking of birds, fishes and other flocking creatures. This project came our nicer than I expected, with some novel additions on my end, so here are some highlights from my report:
Optimised Multithreaded Algorithm
My first implementation of multithreading in psuedo-code looked something like this:
for i = 0 to frame count
make thread group
for each relevant boid (managed by #pragma omp for)
do boid step
for each relevant boid (managed by #pragma omp for)
do update
close thread group
end for
Observe how the boidal update is split into do boid step and do update. The first updates individual boid’s velocities based on surrounding near neighbours, while the second uses each boids velocity to update its position. Splitting this into 2 steps allows a single lock between these steps, rather than a lock on each boid’s position access, neat.
For each frame of the simulation, I would create a thread group of N size, and OpenMP will manage allocating boids to each thread. After executing the boid rules and updating position, the thread group would be destroyed and a new one would be created for the next thread. A rather large improvement I made was creating a thread group for all the frames, and manually allocating which boids are allocated to each thread:
make thread group
calculate which boids are allocated to update
for i = 0 to frame count
wait for other threads
for each allocated boid
do boid step
wait for other threads
for each allocated boid
do update
end for
close thread group
And testing was able to show improvement with 500,000 frames over 4 threads with a variable number of boids (measured in microseconds per frame):
| Boid Count | 20 | 40 | 60 | 80 | 100 |
|---|---|---|---|---|---|
| Old Time | 12 | 28 | 55 | 89 | 130 |
| Improved | 5 | 18 | 39 | 68 | 103 |
Intrestingly, at larger counts with a frame count of 20, the same trend continues, implying my manual allocation is also a contributing factor to the improved performance.
| Boid Count | 2000 | 4000 | 6000 | 8000 | 10000 |
|---|---|---|---|---|---|
| Old Time | 72135 | 286330 | 643796 | 1143673 | 1786425 |
| Improved | 36116 | 143167 | 321982 | 575807 | 893276 |
The important takeaway is to use thread pools over spawning a thread for each workload. Useful for game engines, with my latest using a unified thread pool over the old method of spawning new threads per sync point.
Deterministic Scattering
The regular behaviour for boids can get pretty boring, with the simulation tending towards a single large group. Thus, some sort of scattering to break up groups is generally implemented, with my twist on the formula being deterministic scattering.

Scattering is actually deterministic, with each boid b_i being rotated by 360 * i/N, where N is the total number of boids. This is better for two reasons:
rand()is not thread-safe, thus a lock would be required to avoid race conditions, reducing performance.- Different order of
rand()calls can result in non-deterministic output, even with a lock.
This ended up with a deterministic, performant output, that basically looks random. In future, I think this sort of faux randomness would be interesting to implement. Some sort of array of precomputed random numbers, that are incremented along would be very interesting, especially with a lockless atomic integer incrementer.
Results
Thanks to all the efforts made to avoid locks and other inefficiencies, the final simulation was able to have almost perfect parallelisation.
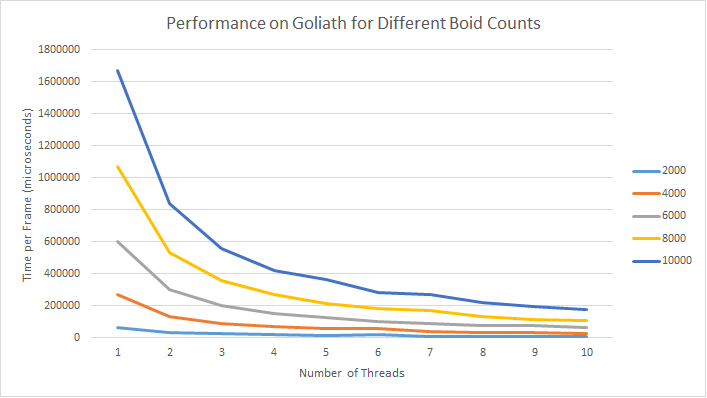
In fact, when performance is compared as a ratio to performance with a single core, it can be seen that the simulation scales almost perfectly.
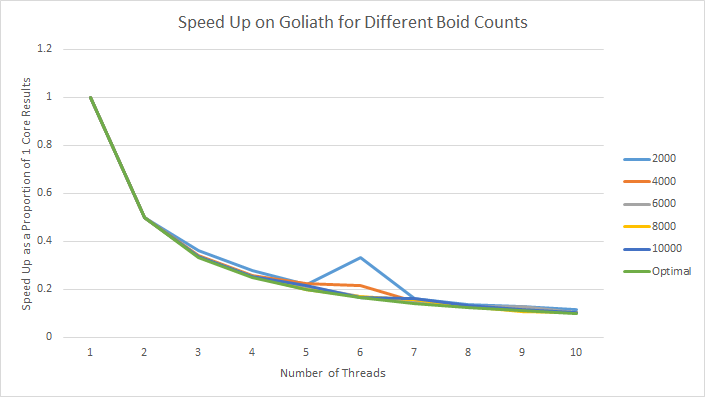
These graphs were also fun to make, with automated scripts really saving the day (and saving me an all-nighter collecting results). Overall, cosc3500 is a great course, and I do recommend it.